量化交易第五节课:基于机器学习的简单的交易策略
2022-08-07 15:20:46
807次阅读
0个评论
最后修改时间:2022-08-09 11:10:50
获取去股票数据
import pandas as pd
import pandas_datareader.data as web
import matplotlib.pyplot as plt
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifierdef load_stock(start_date,end_date,output_file):
try:
df = pd.read_pickle(output_file)
print('load stock data finish')
except FileNotFoundError:
print('file not found')
df = web.DataReader('601318.ss','yahoo',start_date,end_date)
df.to_pickle(output_file)
print('download finish')
return df
zgpa = load_stock(start_date='2017-03-09',end_date='2020-03-05',output_file='601318.pkl')
zgpa.head()
交易条件:如果次日的收盘价高于当日的收盘价,则标记为1,代表次日股票价格上涨,反之,如果次日的收盘价低于当日的收盘价,则标记为-1,代表股票次日价格下跌。这个过程可以为创造股票的交易条件。
定义knn分类函数
def classification_tc(df):
df['Open-Close'] =df['Open']-df['Close']
df['High-Low'] = df['High']-df['Low']
df['target']=np.where(df['Close'].shift(-1)>df['Close'],1,-1)
df = df.dropna()
x =df[['Open-Close','High-Low']]
y =df['target']
return(x,y)
def regression_tc(df):
df['Open-Close'] =df['Open']-df['Close']
df['High-Low'] = df['High']-df['Low']
df['target']=df['Close'].shift(-1)-df['Close']
df = df.dropna()
x =df[['Open-Close','High-Low']]
y =df['target']
return(x,y)拆分数据
x,y=classification_tc(zgpa)
x_train,x_test,y_train,y_test=train_test_split(x,y, train_size=0.8)
knn_clf = KNeighborsClassifier(n_neighbors=95)
knn_clf.fit(x_train,y_train)
print(knn_clf.score(x_train,y_train))
print(knn_clf.score(x_test,y_test))0.5129087779690189
0.5273972602739726使用模型预测的交易信号来进行交易
zgpa['Predict_Signal']=knn_clf.predict(X)
zgpa['Return']=np.log(zgpa['Close']/zgpa['Close'].shift(1))
zgpa.head()
计算基准收益函数
def cum_return(df,split_value):
cum_returns=df[split_value:]['Return'].cumsum()*100
return cum_returns
def strategy_return(df,split_value):
df['Strategy_Return']=df['Return']*df['Predict_Signal'].shift(1)
cum_strategy_return=df[split_value:]['Strategy_Return'].cumsum()*100
return cum_strategy_return
def plot_chart(cum_returns,cum_strategy_return,symbol):
plt.figure(figsize=(9,6))
plt.plot(cum_returns,'--',label='%s Return'%symbol)
plt.plot(cum_strategy_return,label='Stragtegy Return')
plt.legend()
plt.show()
cum_returns = cum_return(zgpa,split_value=len(x_train))
cum_strategy_return=strategy_return(zgpa,split_value=len(x_train))
plot_chart(cum_returns,cum_strategy_return,'zgpa')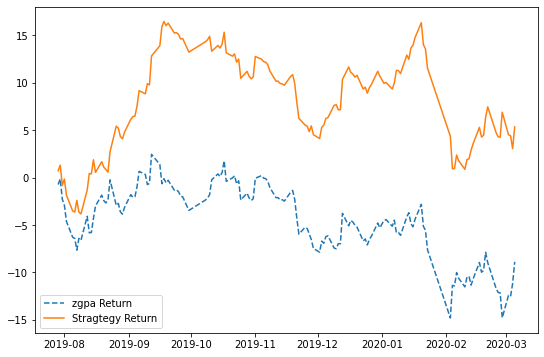
结论:从图中可以看出使用算法交易的累积收益高于该股票的基准收益,如果我们补充因子(或者特征数据)的方法来进一步提高模型的准确率的话,则算法带来的交易还会显著提高。下一节课,我们来讲一下如何补充数据维度,进一步提升模型的性能。
0
0
